Root folder ID ... So if the folder you want rclone to use has a URL which looks like https://drive.google.com/drive/folders/1XyfxxxxxxxxxxxxxxxxxxxxxxxxxKHCh in the browser, then you use 1XyfxxxxxxxxxxxxxxxxxxxxxxxxxKHCh as the root_folder_id in the config.
즉, 웹브라우저에서 Google drive에 접속한 후 mount하고자 하는 특정 폴더로 이동합니다.
이때 주소창에 보이는 주소에서 folders 이후의 주소를 복사해서 config 파일의 root_folder 뒤에 붙여 넣으면 됩니다.
3. 기타
처음에 mount한 경우에 우분투에서 폴더를 생성하거나 파일을 생성하는 경우에 "Input/output error" 문제가 있었고, read only로 mount되는 것을 debug message에서 확인할 수 있었습니다.
웹브라우저로 Google drive에 가서 text 파일을 만들고, 우분투에서 내용을 추가할 수 있었습니다.
우분투(20.04)를 기본 OS로 사용하는데, 필요에 따라서 듀얼 부팅해서 Windows10(최근에 업데이트해서 Windows11)를 사용합니다.
우분투로 부팅해서 사용하다가, 필요에 따라서 윈도우로 부팅해서 작업 후 다시 우분투로 돌아가려고 하는데 부팅이 되지 않습니다. 에러 메시지는 root file system을 찾을 수 없다는 것이었습니다.
우분투 설치 USB로 부팅해서 boot-repair를 실행했는데 "Recommanded repair" 항목이 보이지 않고, "Create a Bootinfo summary" 항목만 보입니다.
검색해 보니 AHCI 모드나 기타 다양한 설명이 있는데 관련이 없었습니다. (BIOS에서 해당 기능을 찾을 수도 없었고, Windows에서 파티션을 암호화하지도 않았습니다.)
어떻게든 부팅시키고 싶은 마음에 Clonezilla로 복원을 시도했는데 백업한 파티션을 확인할 수 없습니다.
다시 우분투 설치 USB로 부팅해서, Disks 프로그램으로 SSD를 확인하는데, 여러 파티션이 아닌 하나로 보이며, 파일시스템의 종류도 확인할 수 없습니다. 윈도우로 부팅해서 SSD를 살펴보면 여러 파티션이 문제없이 보였습니다.
우분투 설치 USB로 부팅 후 mount 명령어를 살펴보니, 평상시 보지 못하던 파티션인 /dev/nvme0n1등의 파티션이 보입니다. SSD는 /dev/sda...에 mount가 되어야 하는데 이상하게 생각되었습니다.
결론적으로 우분투가 SSD의 물리적인 문제가 아니라, 파티션 정보를 인식하지 못하는 문제로 판단했습니다.
이후 단계는 모두 우분투 설치 USB로 부팅 후 진행했습니다
fdisk -l 명령어로 partition들의 정보를 확인해 보니, SSD 파티션 항목에서 "The primary GPT table is corrupt, but the backup appears OK, so that will be used."라는 메시지를 확인할 수 있었습니다. GPT table의 문제로 파티션을 확인할 수 없었던 것입니다.
$ sudo gdisk /dev/nvme0n1
GPT fdisk (gdisk) version 1.0.1
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): r
Recovery/transformation command (? for help): b
Recovery/transformation command (? for help): c
Warning! This will probably do weird things if you've converted an MBR to
GPT form and haven't yet saved the GPT! Proceed? (Y/N): Y
Recovery/transformation command (? for help): v
No problems found. 3437 free sectors (1.7 MiB) available in 2
segments, the largest of which is 2014 (1007.0 KiB) in size.
Recovery/transformation command (? for help): w
참고로 gdisk의 명령어들은 다음과 같습니다.
Command (? for help): ?
b back up GPT data to a file
c change a partition's name
d delete a partition
i show detailed information on a partition
l list known partition types
n add a new partition
o create a new empty GUID partition table (GPT)
p print the partition table
q quit without saving changes
r recovery and transformation options (experts only)
s sort partitions
t change a partition's type code
v verify disk
w write table to disk and exit
x extra functionality (experts only)
? print this menu
본 글은 외장 모니터의 EDID를 읽어서 정상인 경우에만 연결하지 않고, 무조건 연결하는 방법에 대한 것입니다.
외장 모니터(HDMI)를 잘 쓰다가, 갑자기 연결이 되지 않는 문제가 발생했습니다.
xrandr 명령어를 이용하면 HDMI가 연결되지 않았습니다.
$ xrandr
...
DP-1 disconnected (normal left inverted right x axis y axis)
HDMI-1 disconnected (normal left inverted right x axis y axis)
DP-2 disconnected (normal left inverted right x axis y axis)
HDMI-2 disconnected (normal left inverted right x axis y axis)
$ sudo vi /etc/default/grub
# 원래 내용
#GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
# 수정 내용
GRUB_CMDLINE_LINUX_DEFAULT="drm.edid_firmware=HDMI-A-1:edid.bin video=HDMI-A-1:D quiet splash"
위 명령어는 /lib/firmware/ 폴더에 있는 edid.bin 파일을 이용해서 HDMI-A-1를 연결하겠다는 내용으로 이해됩니다.
내용을 저장한 후 grub을 업데이트 해 줍니다.
$ sudo update-grub
이후 다시 부팅했더니 외부 모니터가 정상 동작합니다.
[주의사항]
노트북에서 사용하다 보니 문제점을 확인했습니다.
강제로 EDID를 인식시키는 방법이므로, 외장 모니터가 연결되어 있지 않아도 외장 모니터가 있다고 인식합니다.
따라서 어플리케이션이 다른 화면에 나타나서 컨트롤이 어려울 수 있고, 마우스의 움직임도 이상합니다.
이때는 grub에서 예전에 사용하던 설정으로 변경하여 EDID 파일을 사용하지 않도록 했습니다.
EDID를 외장모니터에 직접 write하는 것도 방법이라고 하는데, 해당 방법은 아직 진행하지 못했습니다.
약 3000 라인이 조금 넘는 text 파일인데, 앞서 자료들을 찾아 읽고 나서인지 기본적인 내용을 파악하기는 힘들지 않았습니다.
주요 내용을 정리하면 다음과 같습니다.
- The protocol consists of an opening handshake followed by basic message framing, layered over TCP.
- The goal of this technology is to provide a mechanism for browser-based applications that need two-way communication with servers that does not rely on opening multiple HTTP connections - The WebSocket Protocol is designed to supersede existing bidirectional communication technologies that use HTTP as a transport layer to benefit from existing infrastructure (proxies, filtering, authentication).
HTTP가 제공하는 기존의 인프라를 이용할 수 있다. - The protocol has two parts: a handshake and the data transfer.
Handshake와 data transfer로 구성된다. - In a handshake, the leading line from the client follows the Request-Line format.
And the leading line from the server follows the Status-Line format. (HTTP Spec.) - After a successful handshake, clients and servers transfer data back and forth in conceptual units referred to in this specification as "messages". On the wire, a message is composed of one or more frames.
Handshake 이후에 메시지들을 주고 받게 된다. - A frame has an associated type. Each frame belonging to the same message contains the same type of data. This version of the protocol defines six frame types and leaves ten reserved for future use.
1.3. Opening Handshake
- For this header field, the server has to take the value (as present in the header field, e.g., the base64-encoded [RFC4648] version minus any leading and trailing whitespace) and concatenate this with the Globally Unique Identifier (GUID, [RFC4122]) "258EAFA5-E914-47DA-95CA-C5AB0DC85B11" in string form, which is unlikely to be used by network endpoints that do not understand the WebSocket Protocol. A SHA-1 hash (160 bits) [FIPS.180-3], base64-encoded (see Section 4 of [RFC4648]), of this concatenation is then returned in the server's handshake.
- The |Sec-WebSocket-Accept| header field indicates whether the server is willing to accept the connection.
1.4. Closing Handshake - By sending a Close frame and waiting for a Close frame in response, certain cases are avoided where data may be unnecessarily lost.
1.5. Design Philosophy - The WebSocket Protocol is designed on the principle that there should be minimal framing. - It is expected that metadata would be layered on top of WebSocket by the application layer, in the same way that metadata is layered on top of TCP by the application layer (e.g., HTTP).
4.1. Client Requirements - The handshake consists of an HTTP Upgrade request, along with a list of required and optional header fields.
5. Data Framing - A client MUST mask all frames that it sends to the server - A server MUST NOT mask any frames that it sends to the client. - Octet i of the transformed data ("transformed-octet-i") is the XOR of octet i of the original data ("original-octet-i") with octet at index i modulo 4 of the masking key ("masking-key-octet-j"): - Control frames are identified by opcodes where the most significant bit of the opcode is 1. Currently defined opcodes for control frames include 0x8 (Close), 0x9 (Ping), and 0xA (Pong). Opcodes 0xB-0xF are reserved for further control frames yet to be defined.
WebSocket is a computer communications protocol, providing full-duplex communication channels over a single TCP connection.
The big difference from REST server is that in an http request you send request and you must wait response to have the data and start new request on the same connection, with the WS you can stream requests and stream responses than operate when you want.
A WebSocket server is nothing more than an application listening on any port of a TCP server that follows a specific protocol.
WebSocket servers are often separate and specialized servers (for load-balancing or other practical reasons), so you will often use a reverse proxy (such as a regular HTTP server) to detect WebSocket handshakes, pre-process them, and send those clients to a real WebSocket server. This means that you don't have to bloat your server code with cookie and authentication handlers (for example).
First, the server must listen for incoming socket connections using a standard TCP socket.
The Sec-WebSocket-Accept header is important in that the server must derive it from the Sec-WebSocket-Key that the client sent to it. To get it, concatenate the client's Sec-WebSocket-Key and the string "258EAFA5-E914-47DA-95CA-C5AB0DC85B11" together (it's a "magic string"), take the SHA-1 hash of the result, and return the base64 encoding of that hash.
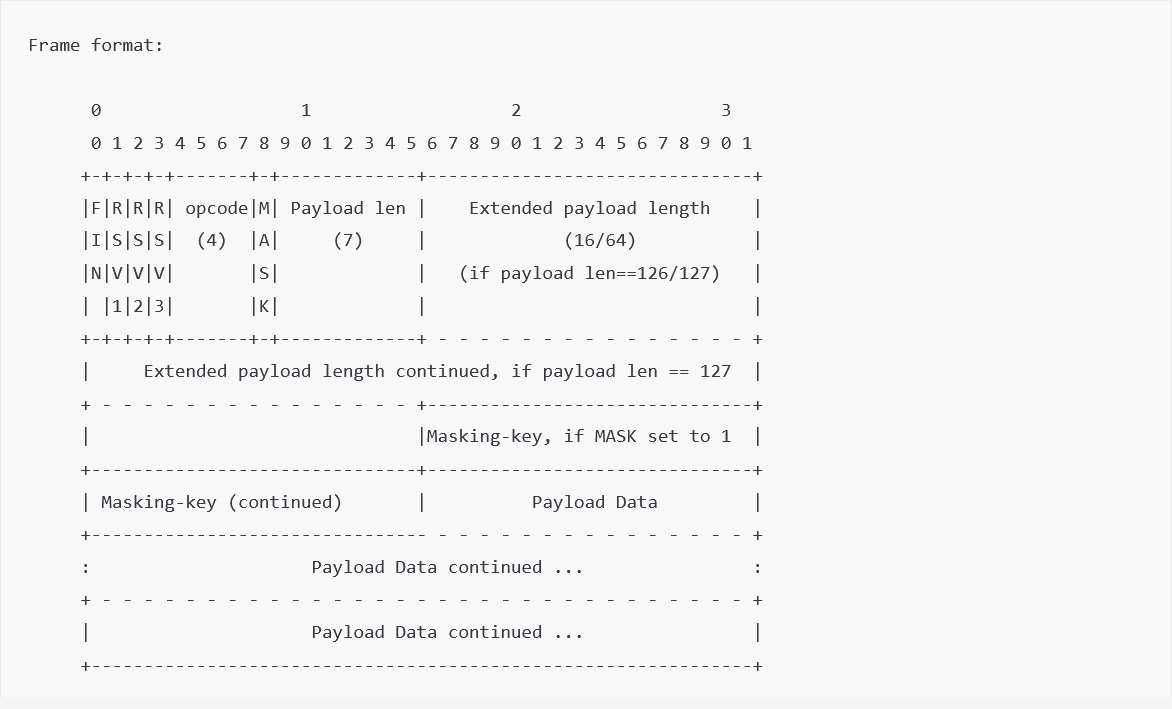
Frame format
내용을 정리하자면 다음과 같습니다.
HTTP와 유사하게 OSI 모델의 7 layer에 위치하는 application
Full duplex로, client의 요청 없이도 서버가 데이터의 전송을 시작할 수 있음
결론적으로 "TCP protocol 상에서 돌아가는 application으로 서버와 clients간에 full duplex를 지원하는 프로토콜" 정도로 이해할 수 있어 보입니다.
원할한 수행을 위해서는 numpy, matplotlib, opencv-python 패키지가 필요합니다.
virtualenv를 이용한 가장 기본적인 환경 설정은 다음과 같습니다.
# virtualenv 환경 설치
virtualenv venv --python=python3
# virtualenv 실행
source venv/bin/activate
# 필요한 패키지 설치
pip install numpy
pip install matplotlib
pip install opencv-python
이후에는 단순히 아래 명령어를 수행하면 됩니다.
python main.py
프로그램이 실행되면서 화면이 계속 변경되는 것을 확인할 수 있습니다.
최종적인 디렉토리 구조는 아래와 같습니다.
├── input
│ ├── detection-results # detection 결과 txt 파일들
│ ├── ground-truth # object 정보 txt 파일들 (정답)
│ └── images-optional # 원본 이미지
└── output # 통계 이미지, output.txt
├── classes # class별 AP 그림
└── images # 원본과 detection 결과를 같이 보여 주는 이미지
└── detections_one_by_one # 각각의 object별 이미지
소스를 처음 받으면 input 폴더와 하위 폴더만 있고, 실행 후에 output 폴더가 생성됩니다.
각 폴더 및 폴더에 포함된 파일들에 대한 상세 설명은 아래와 같습니다.
input/detection-results : 모델을 통해서 얻어진 detection 결과값
input/ground-truth : ground-truth data. 일종의 정답
input/images-optional : 실제 사용한 이미지들
output : 통계 이미지. AP, mAP를 위한 실제 데이터 값 (output.txt)
output/classes : class별 AP 이미지
output/images : detection 정보 및 ground-truth data가 box 형태로 실제 이미지에 표시된 최종 결과 이미지
output/images/detections_one_by_one : detection된 내용이 개별적으로 이미지에 표시된 파일
detection-results에 포함된 "이미지파일명.txt" 파일들의 구성은 다음과 같습니다.
class명 confidence xtl ytl xbr ybr
confidence : 모델이 해당 class로 확신하는 정도. float. %
xtl, ytl : box의 좌측상단 좌표(top left)
xbr, ybr : box의 우측하단 좌표(bottom right)
ground-truth에 포함된 "이미지파일명.txt"는 위와 동일한데, confidence만 없습니다.
이글은 train하고 모델을 변경해서 성능을 향상시키는 것이 목표가 아닙니다. Train을 완료한 config 파일과 weights 파일을 이용해서 테스트 파일을 시험하고, 모델의 성능을 평가하는 것이 주요 목표입니다.
평가를 위해서는 test를 통해서 object를 detect하고, 해당 object로 인식하는 confidence, 위치, 크기등의 정보가 필요합니다. 이를 위해서는 "./darknet detector test" 명령어를 사용하며, git 소스의 src/detector.c에 있는 test_detector() 함수를 직접 호출하게 되는데, 함수의 원형은 다음과 같습니다.
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename,
float thresh, float hier_thresh, int dont_show, int ext_output, int save_labels,
char *outfile, int letter_box, int benchmark_layers)
Arguments들에 대해서 확인한 내용을 정리하면 다음과 같습니다.
datacfg : 데이터 파일
cfgfile : cfg 파일
weightfile : weights 파일
filename : 시험에 사용할 테스트 파일
thesh : object를 인식하기 위한 minimum threshold
hier_thresh : -
dont_show : OpenCV가 있는 경우, 찾은 object를 box로 표시한 그림을 볼 수 있는데, 이를 보지 않도록 하는 옵션
ext_output : 찾은 object의 위치 정보를 console에 출력하기 위한 옵션
save_labels : 찾은 object의 위치 정보를 txt 파일로 자동 저장 (예를 들어 data/dog.jpg를 시험하면, data/dog.txt 파일이 자동으로 생성됨)
outfile :찾은 object의 확률 및 정보등을 json 파일 형식으로 저장하기 위한 옵션
letter_box : box를 letterbox로 그리는 것으로 보임(확인해 보지 않음)
benchmark_layers : -
옵션을 사용하기 위해서 입력해야 하는 변수는 위의 이름과 틀릴 수 있습니다. (hier_thresh가 아니라 -hier을 사용하는등... 자세한 사항은 소스 참조)
이글에서는 save_labels와 outfile 옵션을 소개합니다.
앞선 글에서 설명했듯이, -ext_output 옵션을 사용하면 화면에 detect한 object들의 위치를 출력합니다.
-save_labels 옵션을 사용하면 이미지 파일이 존재하는 폴더에 이미지 파일에서 확장자를 'txt'로 변경한 파일명을 가지는 label 파일이 생성됩니다.
이 label 파일에는 -ext_output의 출력 내용을 map 옵션에서 사용하기 위해서 변경한 최종 내용이 포함됩니다.
예를 들어 data/dog.jpg에서 data/dog.txt 파일이 생성되고, 그 내용은 아래와 같습니다.
- 여기서 'detecor test' 명령에는 data 파일이 사용되는데, data 파일의 형식은 다음과 같습니다. (coco.data 파일에 주석을 달았습니다.)
# #는 주석 표시
# class의 갯수
classes= 80
# train에 사용하는 파일
train = /home/pjreddie/data/coco/trainvalno5k.txt
# validation이나 test에 사용하는 파일
valid = coco_testdev
#valid = data/coco_val_5k.list
# class와 class id를 matching시키기 위한 names 파일
names = data/coco.names
backup = /home/pjreddie/backup/
eval=coco
- 시험에 사용할 파일명( (여기서는 data/dog.jpg)을 맨 마지막에 넣어 줬는데, 파일명이 없는 경우 아래와 같은 메시지가 출력되면서 파일 경로 입력을 기다립니다.
"Enter Image Path:
- 인식 확률이 출력되는데, '-ext_output' 옵션을 추가하면, 검출된 objects의 위치와 크기 정보를 출력합니다.
.txt-file for each .jpg-image-file - in the same directory and with the same name, but with .txt-extension, and put to file: object number and object coordinates on this image, for each object in new line: <object-class> <x> <y> <width> <height>
Where:
<object-class> - integer number of object from 0 to (classes-1)
<x> <y> <width> <height> - float values relative to width and height of image, it can be equal from (0.0 to 1.0]
for example: <x> = <absolute_x> / <image_width> or <height> = <absolute_height> / <image_height>
atention: <x> <y> - are center of rectangle (are not top-left corner)
For example for img1.jpg you will be created img1.txt containing:
- 여기서 X, Y는 이미지의 start point가 아니라, 전체 이미지의 center 값입니다. 내용을 이해하기 어려운데 git source의 script/voc_lable.py의 convert() 함수에 다음 내용이 있습니다.
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
x = x*dw
w = w*dw
여기서 box[0], box[1]은 xmin, xmax로, box[2], box[3]은 ymin, ymax로 이해하면 되며, 이를 수식으로 표시하면 다음과 같습니다.